参考教程:https://www.runoob.com/mysql/mysql-create-database.html
参考博客:https://blog.csdn.net/2301_80913334/article/details/137414543?spm=1001.2014.3001.5501
一、SQL基础
(1)类型:
在SQL中有SQL语言,可以对数据库执行数据查询和数据操作,因此,SQL语言类型可分为:
- 数据查询语言(DQL: Data Query Language)
- 数据操纵语言(DML:Data Manipulation Language)
SQL语句对大小写不敏感!!
(2)结构:
SQL数据库
├── 表 (Table)
│ ├── 列/字段 (Column)
│ │ ├── 数据类型 (Data Type)
│ │ ├── 约束 (Constraints)
│ │ │ ├── 主键 (Primary Key)
│ │ │ ├── 外键 (Foreign Key)
│ │ │ ├── 唯一性 (Unique)
│ │ │ ├── 非空 (Not Null)
│ │ │ └── 检查 (Check)
│ │ └── 默认值 (Default Value)
│ └── 行 (Row)
├── 视图 (View)
├── 索引 (Index)
├── 存储过程 (Stored Procedure)
├── 触发器 (Trigger)
├── 用户 (User)
├── 角色 (Role)
└── 权限 (Permission)表 (Table): 数据库中的基本存储单元,用于存储数据。
- 列 (Column): 表中的字段,每个列都有一个特定的数据类型。
- 数据类型 (Data Type): 定义列中数据的类型,如整数、字符串、日期等。
- 约束 (Constraints): 用于限制列中的数据。
- 主键 (Primary Key): 唯一标识表中的每一行。
- 外键 (Foreign Key): 用于建立表与表之间的关系。
- 唯一性 (Unique): 确保列中的所有值都是唯一的。
- 非空 (Not Null): 确保列中不能有空值。
- 检查 (Check): 确保列中的值满足特定条件。
- 默认值 (Default Value): 如果插入数据时没有指定值,则使用默认值。
- 行 (Row): 表中的记录,每一行代表一个数据项。
视图 (View): 虚拟表,基于SQL查询的结果集。
索引 (Index): 用于加速数据检索的数据结构。
存储过程 (Stored Procedure): 预编译的SQL代码块,可以在数据库中调用。
触发器 (Trigger): 在特定事件(如插入、更新、删除)发生时自动执行的SQL代码。
用户 (User): 数据库的访问者,每个用户都有特定的权限。
角色 (Role): 一组权限的集合,可以分配给用户。
权限 (Permission): 控制用户或角色对数据库对象的访问和操作权限。
(3)SQL固有表:
在MySQL数据库中,自带了一些数据表,他们是是MySQL数据库运行的基础
1. information_schema
存储了整个数据库的宽假结构,在攻击中最为常用,常用表:
TABLES:存储数据库中所有表的信息。
COLUMNS:存储表中所有列的信息。
STATISTICS:存储索引和统计信息。
ROUTINES:存储存储过程和函数的信息。
USER_PRIVILEGES:存储用户的权限信息。
2. performance_schema
performance_schema 主要用于性能监控,可以实时监控数据库的性能指标,如查询执行时间、锁等待、资源使用情况等,主要有以下表:
事件监控
events_waits_current:当前正在发生的事件(如锁等待)。
events_waits_history:最近发生的事件历史记录。
events_waits_history_long:更长时间范围内的事件历史记录。
events_statements_current:当前正在执行的 SQL 语句。
events_statements_history:最近执行的 SQL 语句历史记录。
events_statements_history_long:更长时间范围内的 SQL 语句历史记录。
线程和连接
threads:当前所有线程的信息,包括用户连接和后台线程。
socket_summary_by_instance:按实例统计的套接字连接信息
其他
setup_instruments:定义了哪些事件和指标可以被监控。
setup_consumers:定义了哪些性能数据会被收集和存储。
3. mysql:
mysql库主要用来存储数据库中的基础配置信息,下面是常用表:
用户和权限
- user:存储 MySQL 用户账户及其全局权限。
- db:存储用户对特定数据库的权限。
- tables_priv:存储用户对特定表的权限。
- columns_priv:存储用户对特定列的权限。
- procs_priv:存储用户对存储过程和函数的权限。
插件
- plugin:存储 MySQL 插件的加载状态和配置。
时区
- time_zone:存储时区的基本信息。
- time_zone_leap_second:存储时区的闰秒信息。
- time_zone_name:存储时区名称。
- time_zone_transition 和 time_zone_transition_type:存储时区转换规则。
日志
- general_log:存储通用查询日志(如果启用)。
- slow_log:存储慢查询日志(如果启用)。
其他
- servers:存储远程服务器信息(用于 Federated 存储引擎)。
- help_topic:存储 MySQL 帮助文档的内容。
- func:存储用户自定义函数的信息。
二、DQL(数据查询)类语句
(1)对库的查询
对库的查询就只有一个操作,就是显示数据库名称
show databses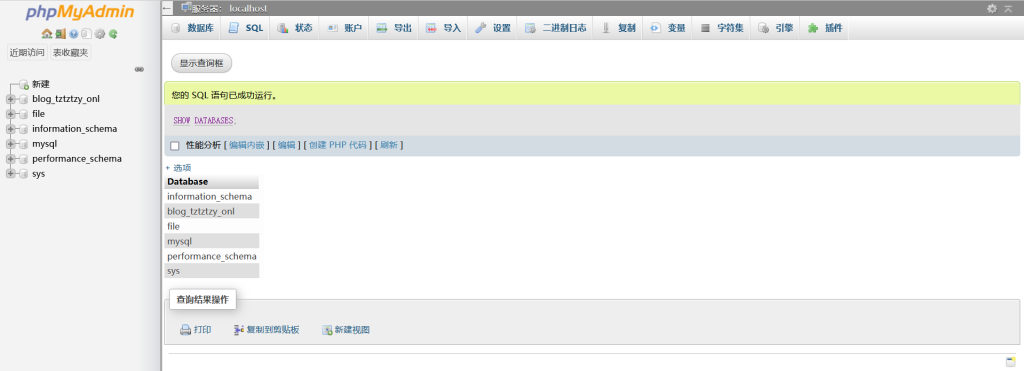
(2)对表的查询
对表的查询是SQL数据库中最常用的操作,下列是常用查询方法:
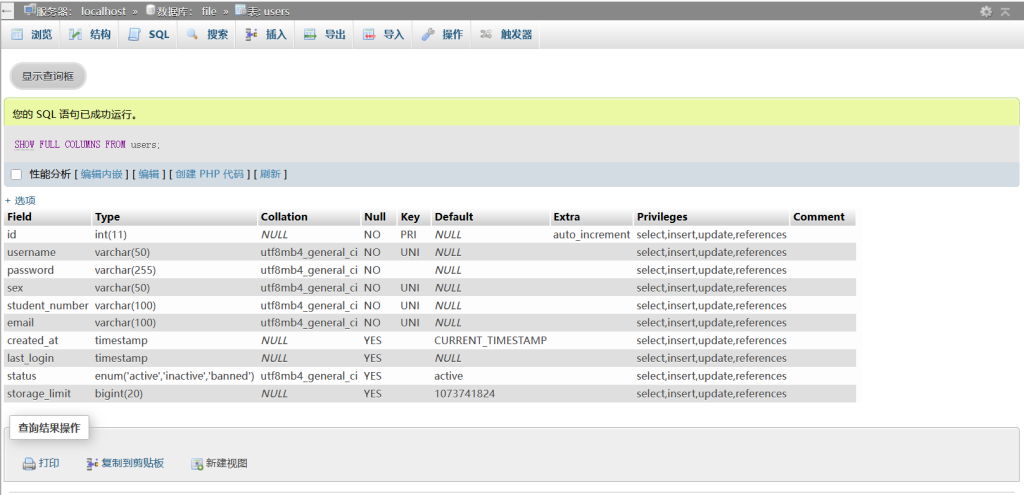
1. 有关表本身信息的查询
SHOW FULL COLUMNS FROM users;这样可以查询出相应表的有关信息
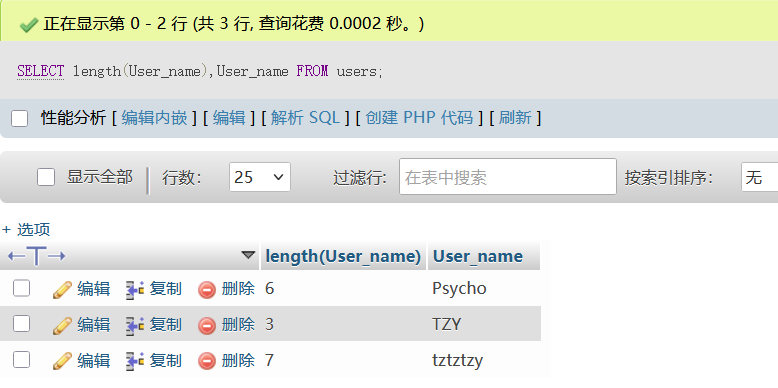
2. 对字段/列(Columns)内容的查询
数据库中的有效信息基本存储在表中的字段中,所以我认为该查询很重要,在一个数据库中,数据库的名称是唯一的
SELECT [DISTINCT] column1, column2, ...
FROM 表名
[WHERE 条件]
[GROUP BY group_column1, group_column2, ...]
[HAVING 条件]
[ORDER BY order_column1 [ASC|DESC], order_column2 [ASC|DESC], ...]
[LIMIT 行数]
[OFFSET 跳过行数];使用时去掉中括号,记得末尾的分号,例如
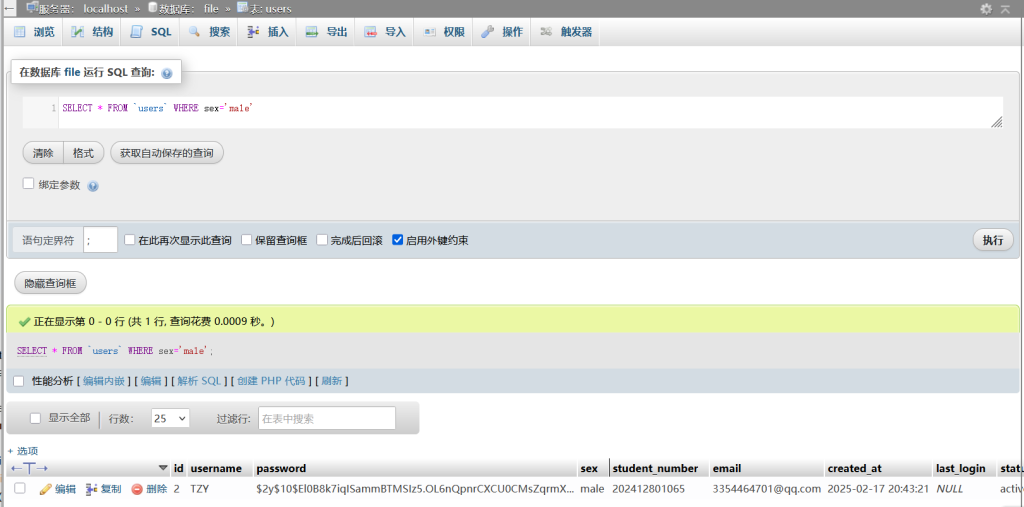
至于行的查询,也是使用对列的查询来实现,通过选取相应字段并限制行数即可实现
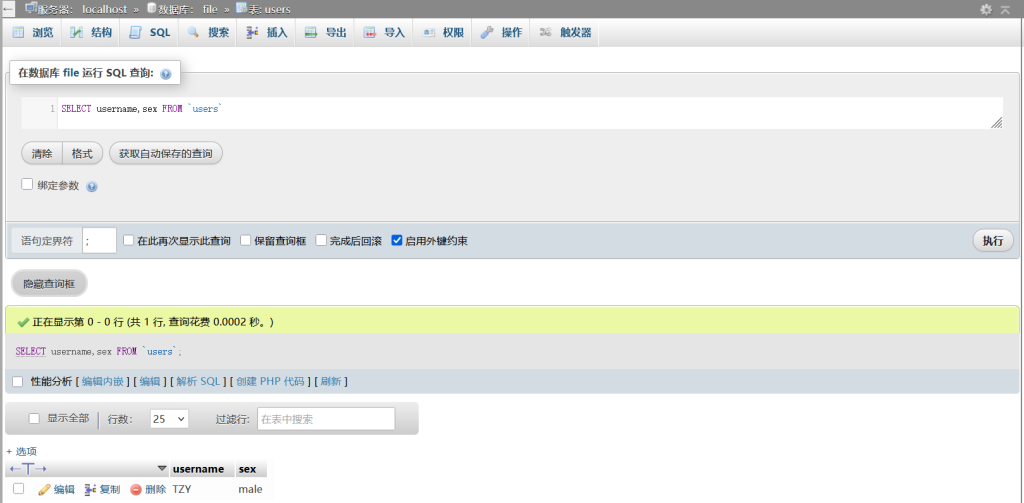
还可以使用UNION SELECT来进行联合查询,语法和SELECT相同,就不多说,主要注意
UNION SELECT查询的内容列数要和前面的SELECT查询内容的列数相同
三、DML(数据操作)语句
(1)对库的操作
1. 创建数据库
CREATE DATABASE 数据库名;
2. 删除数据库
DROP DATABASE <database_name>; -- 直接删除数据库,不检查是否存在
DROP DATABASE [IF EXISTS] <database_name>;参数说明:IF EXISTS是一个可选的子句,表示如果数据库存在才执行删除操作,避免因为数据库不存在而引发错误。database_name是你要删除的数据库的名称。
(2)对表的操作
1. 创建数据表
首先要了解数据库内的数据类型:
https://www.runoob.com/mysql/mysql-data-types.html
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);使用以下语法来实现:
参数说明:
table_name是你要创建的表的名称。column1,column2, … 是表中的列名。datatype是每个列的数据类型。

2. 删除数据表
按照以下方法
DROP TABLE table_name; -- 直接删除表,不检查是否存在
DROP TABLE [IF EXISTS] table_name; -- 会检查是否存在,如果存在则删除参数说明:
- table_name 是要删除的表的名称。
- IF EXISTS 是一个可选的子句,表示如果表存在才执行删除操作,避免因为表不存在而引发错误。
3. 在表中插入数据
当对数据表进行数据写入时,即可使用 INSERT INTO 语句来插入数据
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);上方括号内的字段名和下方的值一一对应写入数据库


4. 更新表内数据
使用 UPDATE 语句可以直接更新表内数据,用法
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;

注意在SQL语句中,字符串也要使用引号进行包裹
5. 删除表内数据
使用 DELETE 语句来删除表内内容
DELETE FROM table_name WHERE condition;参数说明:
- table_name 是你要删除数据的表的名称。
- WHERE condition 是一个可选的子句,用于指定删除的行。如果省略 WHERE 子句,将删除表中的所有行。


6. ALTER 命令
SQL中的ALTER命令可以在不重新创建表的情况下直接更改表的结构
1. 修改表名
- 语法:
ALTER TABLE 旧表名 RENAME TO 新表名;2. 添加列
- 语法:
ALTER TABLE 表名 ADD COLUMN 列名 数据类型 [约束];例如:添加年龄列
ALTER TABLE users ADD COLUMN age INT NOT NULL DEFAULT 0;3. 删除列
- 语法:
ALTER TABLE 表名 DROP COLUMN 列名;例如:删除邮箱列
ALTER TABLE users DROP COLUMN email;注意:若列有约束(如外键),会造成无法更改和删除,要先处理约束
4. 修改列定义
- 修改数据类型:
ALTER TABLE 表名 MODIFY COLUMN 列名 新数据类型;- 重命名列:
ALTER TABLE 表名 CHANGE COLUMN 旧列名 新列名 数据类型;5. 约束管理
- 添加约束(主键、外键、唯一性等):
ALTER TABLE 表名 ADD CONSTRAINT 约束名 约束类型 (列);例如:添加主键
ALTER TABLE users ADD CONSTRAINT pk_user_id PRIMARY KEY (id);- 删除约束:
ALTER TABLE 表名 DROP CONSTRAINT 约束名;6. 默认值操作
- 设置默认值:
ALTER TABLE 表名 ALTER COLUMN 列名 SET DEFAULT 默认值;- 删除默认值:
ALTER TABLE 表名 ALTER COLUMN 列名 DROP DEFAULT;四、SQL高级语句
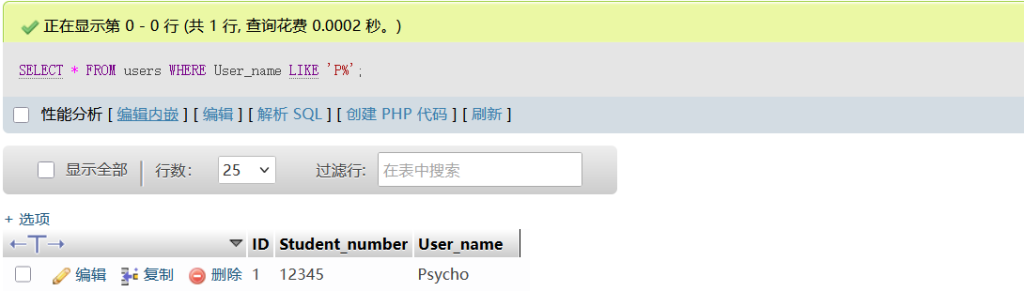
(1)LIKE 语句
这是LIKE与句的通常语法
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;参数说明:
column1,column2, … 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。column_name是你要应用LIKE子句的列的名称。pattern是用于匹配的模式,可以包含通配符。
具体的通配符种类和使用参考
https://blog.csdn.net/qq_36761831/article/details/82857800
(2)IN 操作符
在使用SELECT查询数据时,用于在WHERE语句中指定多个条件,用法:
SELECT column1, column2, ...
FROM table_name
WHERE column IN (value1, value2, ...);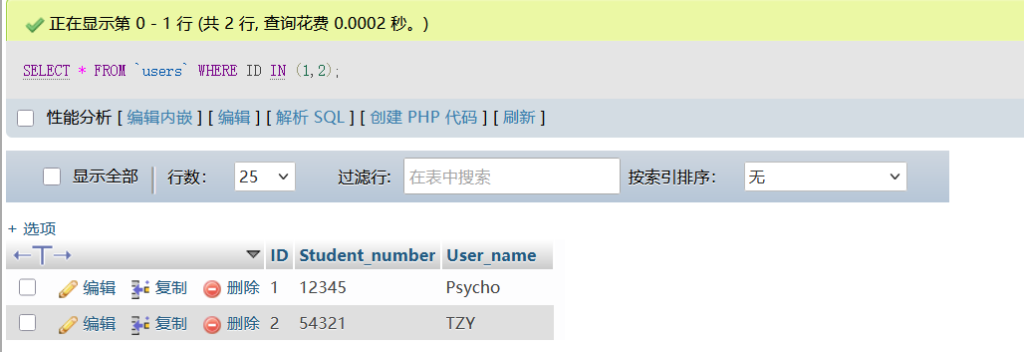
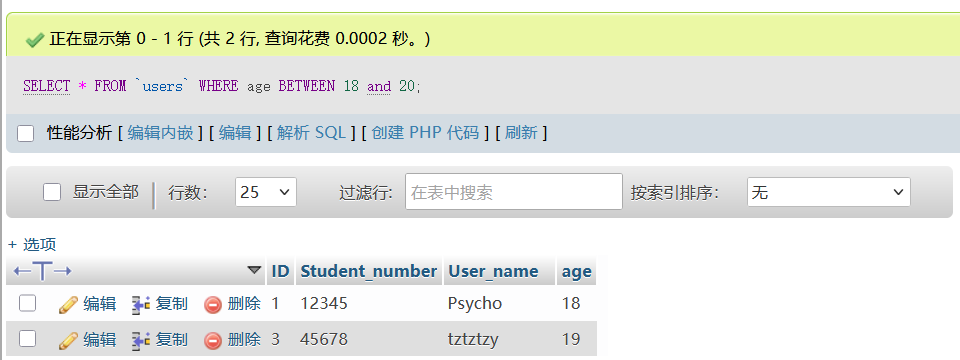
(3)BETWEEN…AND… 语句
BETWEEN 可以选取介于两个值之间的数据范围内的值,这些值可以是数值、文本或者日期。
SELECT column1, column2, ...
FROM table_name
WHERE column BETWEEN value1 AND value2;value1是范围的起始值,value2是范围的结束值,例如
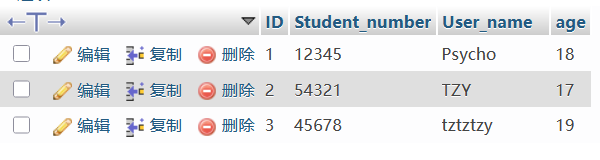
(4)JOIN语句
| 类型 | 描述 |
|---|---|
| INNER JOIN | 返回两个表中满足连接条件的记录(交集)。 |
| LEFT JOIN | 返回左表中的所有记录,即使右表中没有匹配的记录(保留左表)。 |
| RIGHT JOIN | 返回右表中的所有记录,即使左表中没有匹配的记录(保留右表)。 |
| FULL OUTER JOIN | 返回两个表的并集,包含匹配和不匹配的记录。 |
| CROSS JOIN | 返回两个表的笛卡尔积,每条左表记录与每条右表记录进行组合。 |
| SELF JOIN | 将一个表与自身连接。 |
| NATURAL JOIN | 基于同名字段自动匹配连接的表。 |
用法
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;- column1, column2, …:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table1:要连接的第一个表。
- table2:要连接的第二个表。
- condition:连接条件,用于指定连接方式。
五、常用的SQL函数
(1)concat()
将括号中的以逗号分隔的元素拼接起来,不需要有实际数据库也可执行
SELECT concat('hello','world');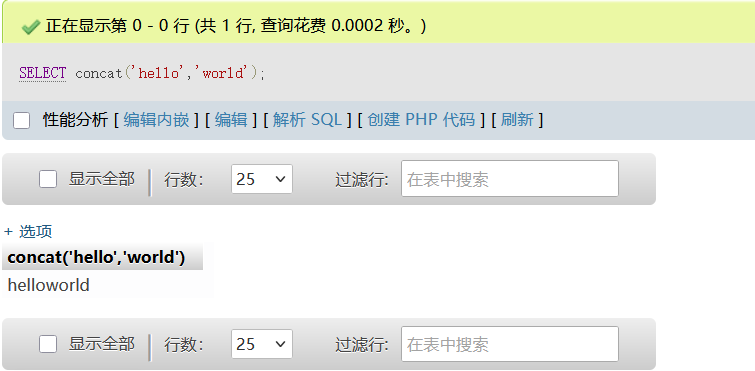
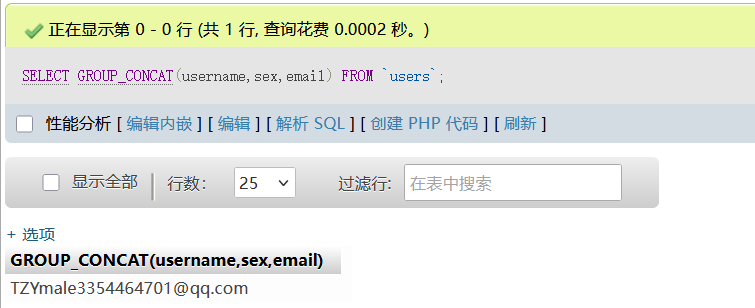
(2)group_concat()
将多行内容拼接为一行并以逗号分隔,SQL注入中常用函数
SELECT GROUP_CONCAT(column1,column2, ...) FROM table_name;例如
(3)ORDER BY
ORDER BY语句对查询结果关于一个或者多个字段进行降序或者升序排列
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;ASC:表示按升序排序, DESC:表示按降序排序。在SQL注入中用来检测一个表的字段数,需要注意的是SQL中计数是从0开始的
(4)GROUP BY
ORDER BY语句对查询结果关于一个或者多个字段进行分组
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name当发现ORDER BY可能被过滤时,可以尝试使用
(5)SELECT DATABASE();
不同于 SHOW DATABASES 的显示全部数据库,SELECT DATABASE(); 可以显示出当前数据库的名称
(6)SELECT VERSION();
跟上一个命令相似,可以回显当前数据库版本
(7)len()
该函数可以回显某个字段的值的长度
SELECT length(column) FROM table_name;